Data Lake vs Data Warehouse: What’s the Difference?


Data lakes and data warehouses are both used to store large amounts of data, but the terms are not interchangeable.
A data lake is not a direct substitute for a data warehouse. They are complementary technologies that serve different use cases, with some overlap, which is why most companies that have one also have the other.
Despite the confusion, the two approaches differ significantly in structure, purpose, and the users they serve. The only real thing they share is that they both store data at scale. Organizations handling sensitive files outside these pipelines often pair them with secure cloud storage to keep documents and data under tighter access control.
This guide breaks down the key differences to help you decide which approach fits your organization.
What is a Data Lake?
A data lake is a popular repository that can hold a large quantity of data while keeping the data's original structure. You can save data that hasn't been assigned a purpose yet. Its uses include dashboard creation, machine learning, and real-time analytics.
When you store a large quantity of data from many sources in one location, it's critical that it's in a concise manner. It should comply with certain laws and regulations and implement encryption to ensure that data security and accessibility are maintained.
Otherwise, only the data lake's design team understands how to access a certain sort of data. It would be impossible to discern between the data you want and the data you are retrieving without adequate information. As a result, it's critical that your data lake does not become a data swamp.
A data lake has a few unique characteristics:
- Source systems are used to load all data. There isn't a single piece of information that isn't considered.
- At the leaf level, data is kept in an untransformed or virtually untransformed condition.
- To meet the demands of analysis, data is changed and schema is applied.
What is a Data Warehouse?
A data warehouse is a collection of technologies, and components used to make strategic data decisions. In order to give actionable business insights, it gathers and maintains data from a variety of sources. It refers to the electronic storing of an enormous volume of data for inquiry and analysis rather than transaction processing. It is the transformation of data into information.
The following are the characteristics of a data warehouse:
-It's an abstracted representation of the company's operations, arranged by subject.
-It has undergone a lot of transformation and has a lot of structure.
-Data isn't entered into the data warehouse until its purpose is determined.
-Ralph Kimball and Bill Inmon established methodologies that are commonly followed.
Key Differences Between Data Lakes and Data Warehouses
Data lakes are frequently equated to data warehouses, although this isn't the case. Data lakes and data warehouses are vastly different from their structure and processing, to who uses them, how data is protected and why they are implemented
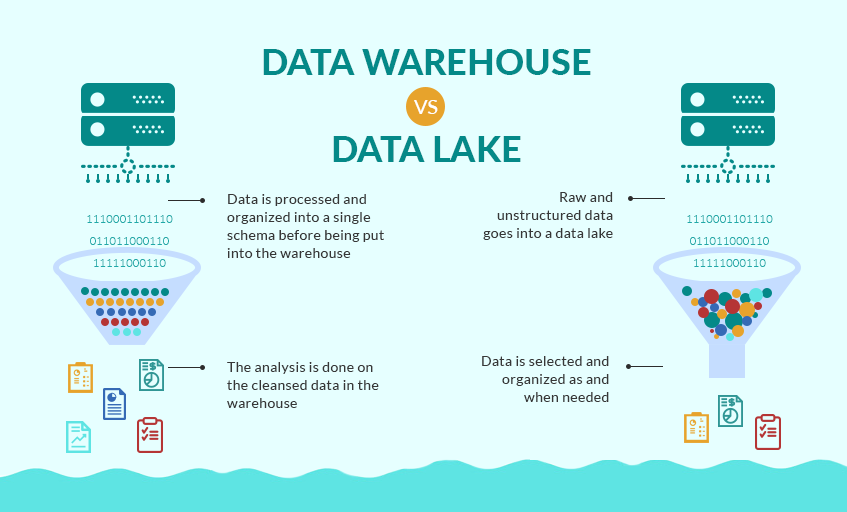
A data lake is not a straight substitute for a data warehouse; rather, they are complementary technologies that serve a variety of use cases, some of which overlap. The majority of companies that have a data lake also have a data warehouse.
Data Types
Unstructured data is data that hasn't been cleansed, and it includes things like photographs, chat logs, and PDF files. Structured data is unstructured data that has been cleaned to suit a schema, organized into tables, and characterized by data types and relationships.
The fundamental distinction between lakes and warehouses is this:
-IoT devices, real-time social media feeds user data, and web application transactions are all sources of data for data lakes. This data is sometimes organized, but it is frequently unstructured since it is ingested directly from the data source.
-Historical data that has been cleansed to match a relational structure is stored in data warehouses. You can also automate the whole process and create data workflows to pass various data types with the ability to manage them better.
Purpose
Data lakes are used to store enormous volumes of data from a variety of sources at a low cost. Allowing data of any form decreases costs since data is more adaptable and scalable because it isn't bound by a schema.
Structured data is easier to examine since it is cleaner and has a consistent format from which to query. Data warehouses are particularly effective for evaluating historical data for specific data decisions because they confine data to a schema.
In a data pipeline, you may find that data lakes and data warehouses complement one another. Data from the firm will be quickly ingested and stored in a data lake. When a specific business question arises, a piece of the lake's data that is judged relevant is collected, cleansed, and exported into a data warehouse.
Users
Different users benefit from data lakes and data warehouses. Data analysts and business analysts frequently operate in data warehouses that include specifically relevant data that has been processed for their purposes.
Data engineers create and maintain data lakes, which they incorporate into data pipelines. Because data lakes contain data of a broader and more current scope, data scientists collaborate more closely with them.
Data warehouses and data lakes are suitable for distinct users:
- Data warehouses are mostly employed by business professionals in the business world.
- Data lakes are mostly employed by data scientists in scientific domains.
Size
It should come as no surprise that data lakes are substantially larger because they store all pertinent data for an organization. A petabyte is a common size for data lakes. What data is saved in data warehouses is far more selective.
Pricing
The cost of storing data is one of the most appealing elements of big data technology. Using big data technology to store data is less expensive than using a data warehouse. This is due to the fact that data technologies are frequently open-source, so license and community support are both free. The data technologies are intended for use with low-cost commodity hardware.
A data warehouse may be expensive to store, especially if the amount of data is huge. A data lake, on the other hand, is made for cost-effective cloud storage.
Security
Unlike big data technologies, data warehouse technologies have been established and in use for decades. Data warehouses are more established and secure than data lakes. Big data technologies, which include data lakes, are still in their infancy. As a result, the capacity to safeguard data in a data lake is still in its infancy.
Which Approach Should You Choose?
The data you collect will be primarily unstructured, whether your company works with healthcare or social media (documents, images). The amount of structured data is really little. As a result, the data lake is an excellent match since it can manage both types of data and provide additional analytical flexibility.
If your online firm is separated into several pillars, you'll want to have dashboards that summarize all of them. In this scenario, data warehouses will aid in making educated judgments. It will ensure that the data is of high quality, consistent, and accurate.
Mostly, businesses needing storage benefit from investing in a combination of the two. They use the data lake for data exploration and analysis before moving the rich data to data warehouses for rapid and advanced reporting.
Final Word
We've looked at the differences between a data lake and a data warehouse in terms of data storage, purpose, and which one to employ in this post. Understanding this notion will aid the big data engineer in selecting the appropriate data storage method and, as a result, optimizing the organization's costs and operations.